About Me
I am currently pursuing my Ph.D. under Dr. Mitesh M. Khapra and co-guided by Dr. Balaraman Ravindran at IIT Madras. I joined IIT Madras as an M.Tech in July 2015, and then converted to Ph.D. programme in March 2017. My area of research is Deep learning for NLP. Currently my work is focussed on modelling better attention mechanism techniques for different Natural Language Generation tasks.
Awards
Google India Ph.D. Fellowship, 2017
Internship
Software Engineering Intern at Google, Zurich : June-September, 2018
Publications
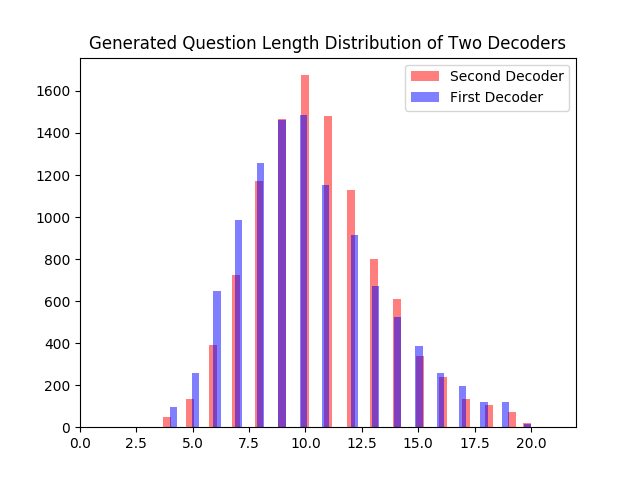
Let's Ask Again: Refine Network for Automatic Question GenerationEmpirical Methods in Natural Language Processing, 2019Preksha Nema*, Akash Kumar Mohankumar*, Mitesh M. Khapra, Balaji Vasan Srinivasan and Balaraman Ravindran |
|
|
In this work we focus on the task of Automatic Question Generation (AQG) where given a passage and an answer the task is to generate the corresponding question. It is desired that the generated question should be (i) grammatically correct (ii) answerable from the passage and (iii) specific to the given answer. An analysis of existing AQG models shows that they produce ` which do not adhere to one or more of these requirements. In particular, the generated questions look like an incomplete draft of the desired question with a clear scope for refinement. To achieve this we propose a method which tries to mimic the human process of generating questions by first creating an initial draft and then \textit{refining} it. More specifically, we propose \textbf{Refine Network (RefNet)} which contains two decoders. The second decoder uses a dual attention network which pays attention to both (i) the original passage and (ii) the question (initial draft) generated by the first decoder. In effect, it refines the question generated by the first decoder thereby making it more correct and complete. We evaluate RefNet on three datasets, \textit{viz.}, SQuAD, HOTPOT-QA and DROP, and show that it outperforms existing state-of-the-art methods by 7-16\% on all of these datasets. Lastly, we show that we can improve the quality of the second decoder on specific metrics, such as, fluency or answerability by explicitly rewarding revisions that improve on the corresponding metric during training. |
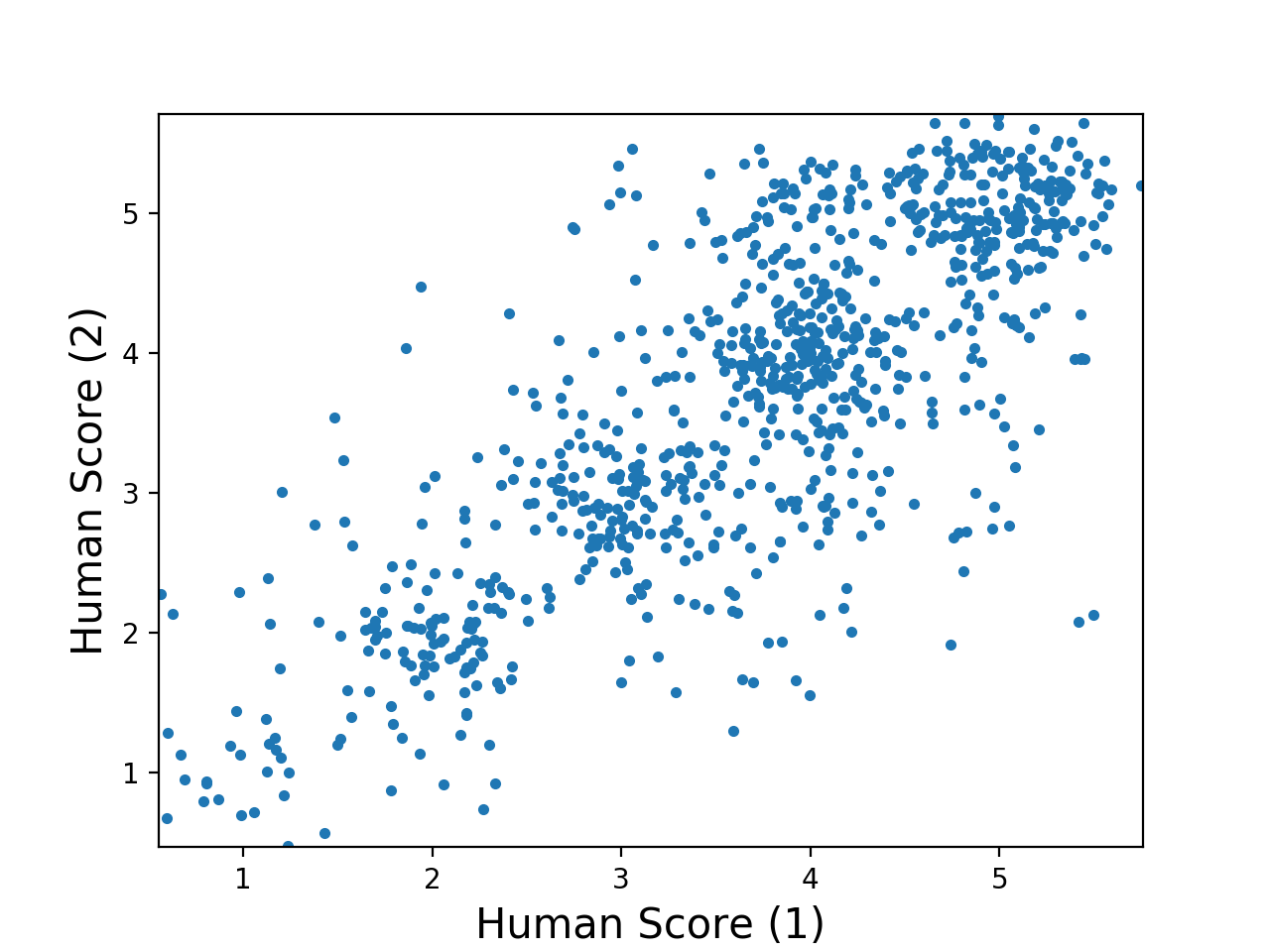
Towards a Better Metric for Evaluating Question Generation SystemsEmpirical Methods in Natural Language Processing, 2018Preksha Nema, Mitesh M Khapra |
|
|
There has always been a criticism for using n-gram based similarity metrics, such as BLEU, NIST, etc. for evaluating the performance of NLG systems. However, these metrics continue to remain popular and are recently being used for evaluating the performance of systems which automatically generate questions from documents, knowledge graphs, images, etc. Given the rising interest in such automatic question generation (AQG) systems, it is important to critically examine whether these metrics are suitable for this task. In particular, it is important to verify whether such metrics used for evaluating AQG systems focus on answerability of the generated question by preferring questions which contain all relevant information such as question type (Wh-types), entities, relations, etc. In this work, we show that current automatic evaluation metrics based on n-gram similarity do not always correlate well with human judgments about answerability of a question. To alleviate this problem and as a first step towards better evaluation metrics for AQG, we introduce a scoring function to capture answerability and show that when this scoring function is integrated with existing metrics they correlate significantly better with human judgments. |
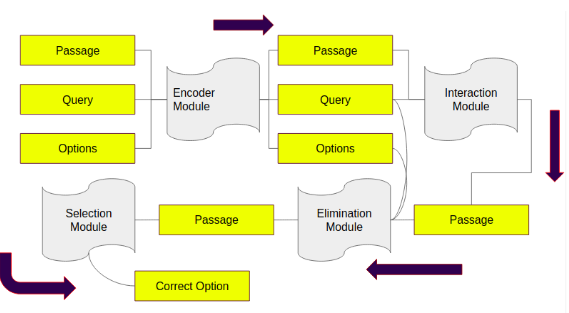
ElimiNet: A Model for Eliminating Options for Reading Comprehension with Multiple Choice QuestionsInternational Joint Conference on Artificial Intelligence (IJCAI), 2018Soham Parikh, Ananya Sai, Preksha Nema, Mitesh M Khapra |
|
|
The task of Reading Comprehension with Multiple Choice Questions, requires a human (or machine) to read a given *{passage, question}* pair and select one of the *n* given options. The current state of the art model for this task first computes a query-aware representation for the passage and then *selects* the option which has the maximum similarity with this representation. However, when humans perform this task they do not just focus on option selection but use a combination of *elimination* and *selection*. This process could be repeated multiple times till the reader is finally ready to select the correct option. We propose *ElimiNet*, a neural network based model which tries to mimic this process. Specifically, it has gates which decide whether an option can be eliminated given the {*passage, question*} pair and if so it tries to make the passage representation orthogonal to this eliminated option (akin to ignoring portions of the passage corresponding to the eliminated option). The model makes multiple rounds of partial elimination to refine the passage representation and finally uses a selection module to pick the best option. |
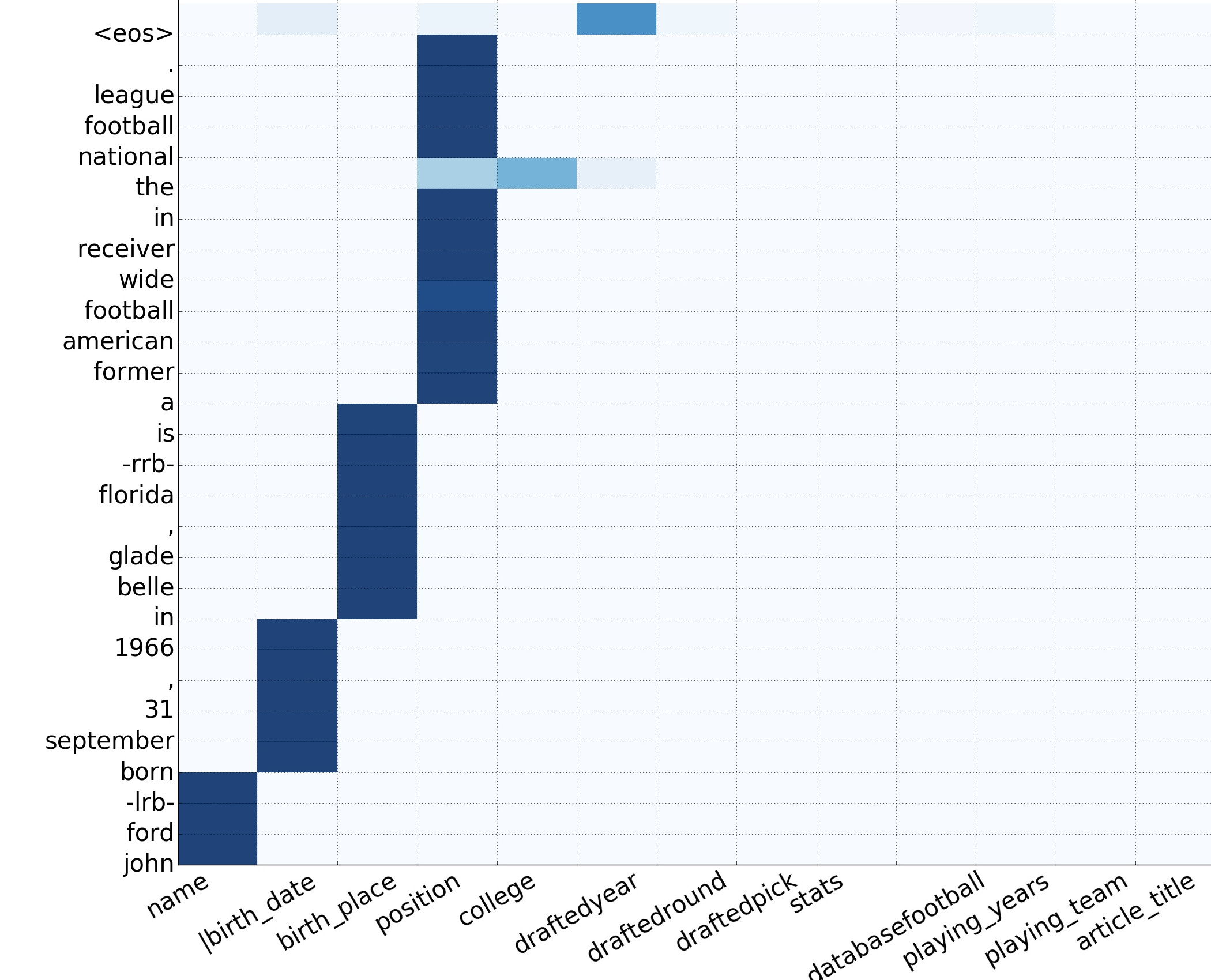
Generating Descriptions from Structured Data Using a Bifocal Attention Mechanism and Gated OrthogonalizationNorth American Chapter of the Association for Computational Linguistics (NAACL), 2018Preksha Nema, Shreyas Shetty M, Parag Jain, Anirban Laha, Karthik Sankaranarayanan and Mitesh M. Khapra | |
|
In this work, we focus on the task of generating natural language descriptions from a structured table of facts containing fields (such as nationality, occupation, etc) and values (such as Indian, {actor, director}, etc). One simple choice is to treat the table as a sequence of fields and values and then use a standard seq2seq model for this task. However, such a model is too generic and does not exploit task specific characteristics. For example, while generating descriptions from a table, a human would attend to information at two levels: (i) the fields (macro level) and (ii) the values within the field (micro level). Further, a human would continue attending to a field for a few timesteps till all the information from that field has been rendered and then never return back to this field (because there is nothing left to say about it). To capture this behavior we use (i) a fused bifocal attention mechanism which exploits and combines this micro and macro level information and (ii) a gated orthogonalization mechanism which tries to ensure that a field is remembered for a few timesteps and then forgotten. We experiment with a recently released dataset which contains fact tables about people and their corresponding one line biographical descriptions in English. |
A Mixed Hierarchical Attention based Encoder-Decoder Approach for Standard Table SummarizationNorth American Chapter of the Association for Computational Linguistics (NAACL), 2018 (Short Paper)Parag Jain, Anirban Laha, Karthik Sankaranarayanan and Preksha Nema, Mitesh M. Khapra and Shreyas Shetty |
|
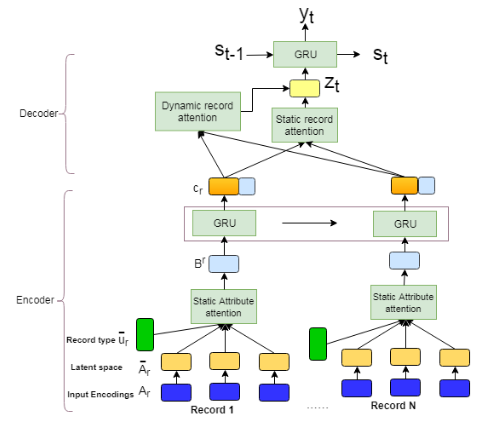
|
Structured data summarization involves generation of natural language summaries from structured input data. In this work, we consider summarizing structured data occurring in the form of tables as they are prevalent across a wide variety of domains. We formulate the standard table summarization problem, which deals with tables conforming to a single predefined schema. To this end, we propose a mixed hierarchical attention based encoder-decoder model which is able to leverage the structure in addition to the content of the tables. Our experiments on the publicly available weathergov dataset show around 18 BLEU improvement over the current state-of-the-art. |
Diversity driven Attention Model for Query-based Abstractive SummarizationAssociation of Computational Linguistics (ACL), 2017Preksha Nema, Mitesh M. Khapra, Anirban Laha, Balaraman Ravindran |
|
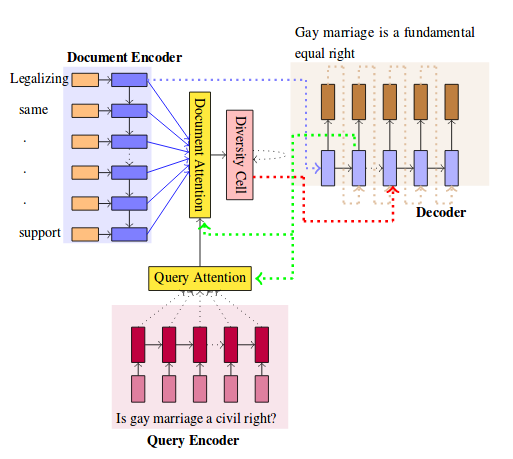
|
Abstractive summarization aims to generate a shorter version of the document covering all the salient points in a compact and coherent fashion. On the other hand, query-based summarization highlights those points that are relevant in the context of a given query. The encode-attend-decode paradigm has achieved notable success in machine translation, extractive summarization, dialog systems, etc. But it suffers from the drawback of generation of repeated phrases. In this work we propose a model for the query-based summarization task based on the encode-attend-decode paradigm with two key additions (i) a query attention model (in addition to document attention model) which learns to focus on different portions of the query at different time steps (instead of using a static representation for the query) and (ii) a new diversity based attention model which aims to alleviate the problem of repeating phrases in the summary. In order to enable the testing of this model we introduce a new query-based summarization dataset building on debatepedia. Our experiments show that with these two additions the proposed model clearly outperforms vanilla encode-attend-decode models with a gain of 28\% (absolute) in ROUGE-L scores. |
Work Experience
I worked at Nvidia Graphics Pvt. Ltd. from June 2012 - June 2015 as a System Software Engineer in Resource Manager- Professional Soultions Group team.
Academic Details
I have completed my B.Tech from Visvesvaraya National Institute of Technology, Nagpur in Computer Science and Engineering in 2012.
Contact:
preksha [at] cse[dot]iitm[dot]ac[dot]in
preksha [dot] nema9 [at] gmail [dot] com